在学习初期就对与头文件和链接有些迷茫,今天简单谈谈这些事情。
从源代码到可执行文件
使用g++/gcc 工作流程如下
预处理:宏的展开,头文件展开,条件编译,去除注释等操作。
编译和汇编就不再叙述
链接:将目标代码中用到的所有相关的代码链接在一起,比如各种库函数和自己定义的各种函数。
预处理和链接
初学的时候,我迷惑的点在于,既然预处理已经展开头文件,那么链接又在链接什么?直到自己完成了lept_json这个完整的项目之后,才对这个问题有了更加清晰的认识。
首先了解一下gcc/g++ 的用法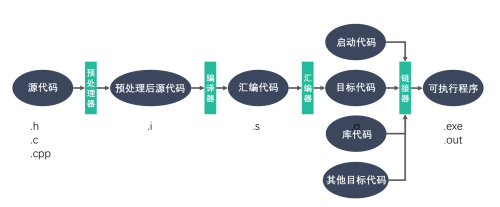
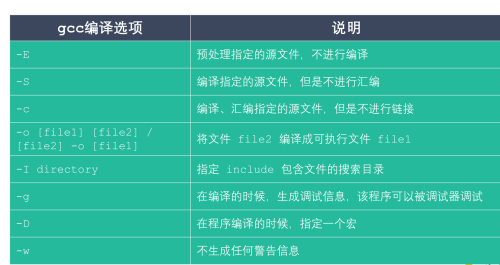
-o 也可以用来指定生成的文件的名称,否则会为默认文件名。
1 | ---test.cpp--- |
g++生成可执行文件的命令如下
1 | g++ -c test.cpp -o test.o |
或者直接
1 | g++ test.cpp head_file1.cpp -o test // 文件的先后顺序不影响正确性 |
在实际开发过程中,良好的习惯是将函数的声明和定义分开,声明写在 xxx.h,定义写在 xxx.cpp。例子中 fun() 的定义和声明就是分开的
预处理就是将头文件展开,也就是将head_file1.h 中的 fun函数声明 在 test.cpp 中展开。
预处理过后 test.cpp中有了fun函数的声明,在接下来的编译过程中,它是符合规范的,即便现在编译器并不知道fun函数的定义。
链接过程中,链接器看到fun函数的声明,会去找fun函数的定义,那么怎么找到fun函数的定义呢?
我们将fun函数定义在了 head_file1.cpp中,因此就需要将 head_file1.cpp的目标代码(head_file1.o) 和test.cpp的目标代码(test.o) 链接起来生成 可执行文件
在第一种方法中
1 | g++ -c test.cpp -o test.o // 生成目标代码 test.o 该文件中含有fun函数的声明但并没有定义 |
1 | g++ test.cpp head_file1.cpp -o test // 两个文件一起处理,作用和第一种方法是一致的 |
一些问题
1
也许有人会想着先处理头文件对应的head_file1.cpp 然后处理 test.cpp
1 | g++ head_file1.cpp -o test |
这样是错误的,因为head_file1.cpp 中并没有main()函数,因此链接会出现错误,所以我们只能生成目标代码,也就是使用 -c 这个命令,停留在链接之前,然后和test.o 一起链接处理,test.o中是有main()函数的哦。
2
linux中文件的后缀其实并没用,我们只是习惯 .o .s .cpp 这些;
head_file1.cpp 并不一定要和 head_file1.h 的名字一样,只是这样更加规范一些,g++是不会在乎这些名字的,因为 .h文件 是在预处理阶段展开的, 对应的 .cpp 文件是在链接阶段和test.o 链接在一起的,链接器并不是根据名字找到头文件对应的.cpp后缀的源代码的(当然,链接时候已经变成了 .o 后缀的目标代码)。
3
三个文件都引用了标准库,但并没有重复定义的问题,为什么?
第一,我们可以使用
1 | //条件编译 |
标准库中都含有条件编译指令
这些指令来避免重复定义(也能避免重复声明,但是重复声明只是会增加代码体积而已),但是请注意条件编译指令是在预处理阶段进行的,也就是说
这里针对的都是在一个.cpp文件中避免头文件重复引入。如果一个工程有多个”.cpp”文件,由于编译器对每个.cpp文件是分开处理的,只在最后进行链接。在这种情况下,如果有多个.c文件都直接或间接引入了某个头文件,这时无法避开的。
我们的 head_file1.h 和 test.cpp 都引用库函数,但是在预处理阶段就已经处理掉了,只会引用一次。但是这两个文件(test.cpp head_file1.cpp)都有标准库啊,链接时候怎么没出错呢?
这就是定义和声明分开的好处,我们引用的头文件是标准库各种函数的声明,而不是定义,而重复声明并没关系(当然为了节省代码体积,减少内存开销,最好能不用头文件就不用,不要一股脑把可能用到的库函数头文件全部写上),在链接的时候,库函数对应的 .o 文件会和我们的目标代码链接, 链接器虽然看到了那么多头文件库函数声明,但是对应的 库函数 .o 代码,链接器只会链接一次,避免出现重复定义错误。
1 | ---test.cpp--- |