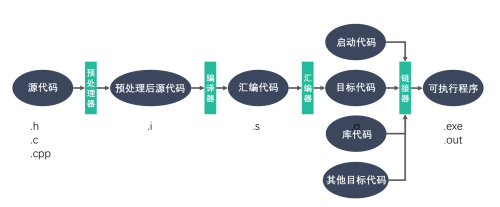
启程 配环境
vscode+remote-ssh+云服务器centos8开发
本想写2023年的新版lab,但是看了看要用g++20编译,试了试更新g++太难,放弃了,期间还删掉了g++,还好服务器有备份可以回滚。
推荐使用 https://kangyupl.gitee.io/cs144.github.io/ 网站镜像备份,g++8编译就可以。
代码也是采用 https://gitee.com/kangyupl/sponge git clone 下来后直接切换分支就可以写。
编译 make
lab0 中规中矩,热身实验。耗时1.5h左右。
实现 get_url函数,注意端口号部分写 http 代表服务类型就行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Address (const std::string &hostname, const std::string &service); void get_URL (const string &host, const string &path) TCPSocket mysock; mysock.connect (Address (host,"http" )); mysock.write ("GET " +path+" HTTP/1.1\r\n" ); mysock.write ("Host: " +host+"\r\n\r\n" ); mysock.shutdown (SHUT_WR); while (!mysock.eof ()){ auto rec_message=mysock.read (); cout<<rec_message; } mysock.closed (); return ; }
内存中的通讯,采取了list的写法。注意下eof() 函数,头文件注意定义变量,别定义少了。
就是一个可以读取和写入的有序字节流,先写入的先被读取到。实现这个类的一些方法。
1 2 3 4 5 6 7 8 9 10 private : bool _error{}; std::list<char > stream_content; const size_t capacity= 0 ; size_t stream_size=0 ; bool flag_finish=0 ; size_t read_size=0 ; size_t writen_size=0 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 ByteStream::ByteStream (const size_t mycapacity) : stream_content{}, capacity (mycapacity), stream_size (0 ) {} size_t ByteStream::write (const string &data) if (flag_finish || _error) return 0 ; size_t temp_size = writen_size; for (auto & temp : data) { if ((writen_size-read_size ) >= capacity) break ; stream_size++; writen_size++; stream_content.emplace_back (temp); } return (writen_size - temp_size); } string ByteStream::peek_output (const size_t len) const { if (_error) return nullptr ; size_t temp_len = 0 ; string ans (len, '0' ) ; for (auto temp_char : stream_content) { if (temp_len == len) break ; temp_len++; ans[temp_len - 1 ] = temp_char; } return ans.substr (0 , temp_len); } void ByteStream::pop_output (const size_t len) if (_error) return ; size_t cur_size=buffer_size (); for (size_t i = 0 ; i < len; i++) { if (cur_size<= 0 ) break ; cur_size--; stream_content.pop_front (); read_size++; } return ; } void ByteStream::end_input () flag_finish = 1 ; return ; } bool ByteStream::input_ended () const return flag_finish; }size_t ByteStream::buffer_size () const return writen_size-read_size; }bool ByteStream::buffer_empty () const return writen_size-read_size==0 ; }bool ByteStream::eof () const return buffer_empty () && flag_finish; } size_t ByteStream::bytes_written () const return writen_size; } size_t ByteStream::bytes_read () const return read_size; }size_t ByteStream::remaining_capacity () const return capacity - (writen_size-read_size); }
lab1 实现一个类,把无序可能重复到达的数据组合成有序的并且写入到_output中,_output就是lab0实现的Bytestream。耗时3.5h左右。
写之前可以先make测试一下,看看测试程序的样例,不然理解可能会有些偏差,我盯着样例看了一会才明白具体细节。
注意点如下
到达数据会重叠
当到达数据全部被接受到(根据传入参数eof判断),且全部有序后,且全部写入output后,需要更新output的结束信号状态。
output的容量可能比StreamReassembler的小,不过这个lab中不用考虑这些…不知道为什么,考虑的话,当output的可用容量小于要写入的字节时候,你还要自己做个判断,并且定义一个新的变量。
按照道理,流重组器的数据写入顺序字节流后,流重组器的数据就可以删除了,不过这个lab没要求,我也懒得写,也不知道后面lab需不需要考虑。
网上一个参考说明如下,不过这个lab其实并不用考虑
LAB0的顺序字节流和LAB1的流重组器各有各的容量限制。流重组器把字节流写满后,只有当字节流腾出空后才能继续写,相当于字节流满时流重组器出口被“堵住”了。同样当流重组器容量满了后自身也无法被写入新数据,此时到来的新碎片只能被丢弃掉。
选取合适数据结构很重要,写之前模拟半天,一个idea是两个链表,太复杂pass了,一个idea是双端队列+无序set,一个idea是string+无序set。
需要删除流重组器的数据的话用deque更好一些,不过我写的时候没考虑,直接用了string。 到时候看看再重构吧。
写完lab1 做lab2的时候我才知道
lab1的担心是对的,确实需要删除已经写入有序字节流的元素,把lab2代码拉下来后重新测试发现lab1出错了,lab2新增了对lab1的测试,也就是测试有没有删掉已经写入顺序字节流的元素,所以fix bug采用了deque数据结构。
以下是最新代码
1 2 3 4 5 6 7 8 9 10 11 12 private : ByteStream _output; size_t _capacity; std::deque<char > all_content_str; std::unordered_set<int > hash_str_unorderset={}; size_t size_char_inorder=0 ; size_t size_char_all=0 ; size_t size_char_writen=0 ; size_t start_index=0 ; bool eof_flag=false ;
具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 StreamReassembler::StreamReassembler (const size_t capacity) : _output(capacity), _capacity(capacity), all_content_str (capacity, '0' ) {} void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) size_t data_length = data.size (); size_t up_length = min (data_length , _capacity+start_index-index); for (size_t i = 0 ; i < up_length; i++) { if (hash_str_unorderset.find (i+index) == hash_str_unorderset.end ()) { hash_str_unorderset.emplace (i+index); all_content_str.at (index-start_index+i) = data[i]; size_char_all++; } } for (size_t i = size_char_inorder-start_index; i < _capacity; i++) { if (hash_str_unorderset.find (i+start_index) == hash_str_unorderset.end ()) break ; size_char_inorder++; } size_t size_writable=min (_output.remaining_capacity (),size_char_inorder-size_char_writen); string temp (size_writable,'0' ) ; for (size_t i=0 ;i<size_writable;i++) temp[i]=all_content_str.at (i); _output.write (temp); for (size_t i=0 ;i<size_writable;i++){ all_content_str.pop_front (); all_content_str.emplace_back ('0' ); }; size_char_writen+=size_writable; start_index=size_char_writen; if (eof) eof_flag=true ; if (eof_flag && this ->empty ()){ _output.end_input (); } return ; } size_t StreamReassembler::unassembled_bytes () const return size_char_all - size_char_inorder; }bool StreamReassembler::empty () const return size_char_all == size_char_inorder && size_char_inorder==size_char_writen; }
lab2 花费比较多,8h左右。 tcp receiver
part1 对我挺折磨的,主要是看不懂文档在说啥…,真正理解还是自己测试的时候,看测试代码才知道究竟让干啥,一些细节究竟是什么。
注释比较全面了,不过我的逻辑可能不太好理解,有问题可以给我提issue。
cout是debug时候看的,留着可能下个lab还要用,悲,测试样例不全就是这样的,不能相信之前自己写的lab。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 WrappingInt32 wrap (uint64_t n, WrappingInt32 isn) { uint64_t t_num = UINT32_MAX; t_num++; n = n % (t_num); n += isn.raw_value (); n = n % (t_num); return WrappingInt32 (static_cast <uint32_t >(n)); } uint64_t unwrap (WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) cout << " n isn check " << n << " " << isn << " " << checkpoint << endl; WrappingInt32 check_in_wrap32 = wrap (checkpoint, isn); cout << " check in warp32 " << check_in_wrap32 << " " << endl; uint64_t ans = 0 ; uint64_t gap_1 = 0 ; uint64_t gap_2 = 0 ; uint64_t n_raw_value = n.raw_value (); uint64_t check_in_wrap32_raw_value = check_in_wrap32.raw_value (); if (n_raw_value < check_in_wrap32_raw_value) { gap_1 = 1 + n_raw_value + (uint64_t )UINT32_MAX - check_in_wrap32_raw_value; } else gap_1 = n_raw_value - check_in_wrap32_raw_value; if (n_raw_value > check_in_wrap32_raw_value) { gap_2 = 1 + (uint64_t )UINT32_MAX + check_in_wrap32_raw_value - n_raw_value; } else gap_2 = check_in_wrap32_raw_value - n_raw_value; if (gap_1 < gap_2) { ans = checkpoint + gap_1; } else if (checkpoint >= gap_2) ans = checkpoint - gap_2; else ans = checkpoint + gap_1; return ans; }
part2 认真看文档,先理解让干啥再写,我漏看了后面的详细介绍,懵逼了半天,不知道从何下手,然后又看文档才发现后面有详细的介绍。
逻辑不难,本质上就是维护一个滑动窗口,然后确认什么时候接收数据,什么时候不接受。需要注意的是,这里的窗口大小被有序字节流和重组器的共同限制,这下知道我怎么发现lab0的bug了吧。需要注意的细节有点多,慢慢对着测试代码改吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private : StreamReassembler _reassembler; size_t _capacity; size_t seg_length = 0 ; bool seg_syn_flag = false ; bool seg_fin_flag = false ; uint64_t checkpoint{0 }; uint32_t offset_syn = 0 ; WrappingInt32 syn_num{0 }; WrappingInt32 seq_num{0 };
具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 bool TCPReceiver::segment_received (const TCPSegment &seg) if (seg.header ().syn) { if (seg_syn_flag) return false ; offset_syn = 1 ; seg_syn_flag = true ; syn_num = seg.header ().seqno; checkpoint = static_cast <uint64_t >(0 ); } if (!seg_syn_flag) return false ; if (seg.header ().fin && seg_fin_flag) return false ; if (seg.header ().fin) seg_fin_flag = true ; WrappingInt32 temp_seq_num{seg.header ().seqno}; uint64_t temp_cur_index = unwrap (temp_seq_num + offset_syn, syn_num, checkpoint); cout<< " 收到的数据段的绝对序列号 " <<temp_cur_index<<endl; if (_reassembler.ack_n () + 1 + _reassembler.empty_length () <= temp_cur_index){ return false ; cout<<" 当前段的序列超过窗口范围 丢弃 " <<endl; } seg_length = seg.length_in_sequence_space ()-seg.header ().syn-seg.header ().fin; if (seg_length==0 ){ if (wrap (temp_cur_index, syn_num)-wrap (_reassembler.ack_n () + 1 , syn_num) <0 ){ return false ; } } else if (wrap (temp_cur_index, syn_num) + static_cast <uint32_t >(seg_length-1 +seg.header ().fin) -wrap (_reassembler.ack_n () + 1 , syn_num) <0 ){ cout<<" 判断接受到的 重叠且这个数据段没有新的信息 直接丢弃 " <<endl; return false ; } seq_num = seg.header ().seqno; uint64_t cur_index = unwrap (seq_num + offset_syn, syn_num, checkpoint); checkpoint = cur_index + seg_length - 1 ; cout<<" 进入重组 " <<cur_index<<endl; _reassembler.push_substring (seg.payload ().copy (), cur_index - 1 , seg_fin_flag); offset_syn = 0 ; return true ; } optional<WrappingInt32> TCPReceiver::ackno () const { if (seg_syn_flag == false ) return nullopt ; uint64_t n = _reassembler.ack_n () + 1 ; cout<<" 期望收到的绝对序列号n " <<n<<endl; return wrap (n, syn_num); } size_t TCPReceiver::window_size () const return _reassembler.empty_length (); }
在lab1中的流重组器中加了两个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 uint64_t empty_length () const uint64_t ack_n () const uint64_t StreamReassembler::ack_n () const if (eof_flag) return size_char_inorder + 1 ; return size_char_inorder; } uint64_t StreamReassembler::empty_length () const return min (_output.remaining_capacity ()-(size_char_inorder-size_char_writen), _capacity - (size_char_inorder - size_char_writen)); }
中期总结 lab0实现了内存中的顺序读取结构,也就是bytestream。
lab1在此基础上实现了重组器,把不按照顺序到达的数据重新组装起来,流重组器控制传入数据读取多少,需要读取哪些数据,下一个需要读取的数据序号(ack的序号)。
lab2在两者基础上维护了一个滑动窗口,根据窗口大小,还有数据的序号关系,各种特殊情况怎么处理,选择是否接受数据,把数据传入流重组器(数据接收并不一定被全部接收,可能被流重组器部分接收,不过这不需要管,只要有数据需要被接收就传入流重组器,receiver不需要考虑接收多少,这是流重组器需要处理的)。
lab3 实现tcp sender
根据远方接收者的窗口内可接收新数据的长度 以及 我们可以发送的数据长度 发送tcp segment给receiver。
当然也要实现最开始发送syn空报文,结束发送fin报文的功能。
重传机制:设置重传计时器和超时时间,收到新的报文ack就重新启动重传计时器和超时时间,超时就需要重传最小的未被确认的报文。
未被确认的报文都需要进行缓存,确认后再pop出去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private : WrappingInt32 _isn; std::queue<TCPSegment> _segments_out{}; std::queue<TCPSegment> _segments_wait{}; unsigned int _initial_retransmission_timeout; ByteStream _stream; uint64_t _next_seqno{0 }; bool syn_sent=false ; bool fin_sent=false ; size_t remote_window_size=1 ; size_t cur_all_time=0 ; size_t next_retran_time=0 ; bool tcp_timer_running=false ; size_t cur_rto=0 ; size_t continuous_retran_num=0 ; uint64_t cur_bytes_length_in_flight=0 ;
具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 TCPSender::TCPSender (const size_t capacity, const uint16_t retx_timeout, const std::optional<WrappingInt32> fixed_isn) : _isn(fixed_isn.value_or (WrappingInt32{random_device ()()})) , _initial_retransmission_timeout{retx_timeout} , _stream(capacity) , syn_sent{false } {} uint64_t TCPSender::bytes_in_flight () const return cur_bytes_length_in_flight; }void TCPSender::fill_window () if (fin_sent) return ; if (syn_sent == false ) { TCPSegment syn_seg; syn_seg.header ().syn = true ; syn_seg.header ().seqno = _isn; _next_seqno=1 ; _segments_out.push (syn_seg); _segments_wait.push (syn_seg); syn_sent = true ; if (tcp_timer_running==false ) { tcp_timer_running = true ; cur_rto = _initial_retransmission_timeout; next_retran_time = cur_all_time + cur_rto; continuous_retran_num = 0 ; } cur_bytes_length_in_flight = static_cast <uint64_t >(syn_seg.length_in_sequence_space ()); return ; } size_t cur_send_size = min (_stream.buffer_size (), (remote_window_size - static_cast <size_t >(cur_bytes_length_in_flight))); size_t temp_i = 1450 ; size_t seg_num = cur_send_size / temp_i; size_t end_length=cur_send_size-seg_num*temp_i; if (cur_send_size > 0 ) seg_num++; if (cur_bytes_length_in_flight<remote_window_size && _stream.eof ()){ fin_sent = true ; TCPSegment fin_seg; fin_seg.header ().fin = true ; fin_seg.header ().seqno = wrap (_next_seqno, _isn); _next_seqno += static_cast <uint64_t >(fin_seg.length_in_sequence_space ()); _segments_out.push (fin_seg); _segments_wait.push (fin_seg); if (tcp_timer_running==false ) { tcp_timer_running = true ; cur_rto = _initial_retransmission_timeout; next_retran_time = cur_all_time + cur_rto; continuous_retran_num = 0 ; } cur_bytes_length_in_flight += static_cast <uint64_t >(fin_seg.length_in_sequence_space ()); return ; } for (size_t i = 0 ; i < seg_num; i++) { if (tcp_timer_running == false ) { tcp_timer_running = true ; cur_rto = _initial_retransmission_timeout; next_retran_time = cur_all_time + cur_rto; continuous_retran_num = 0 ; } string temp_seg_content; if (i==seg_num-1 ) temp_seg_content = _stream.peek_output (end_length); else temp_seg_content = _stream.peek_output (temp_i); _stream.pop_output (min (temp_i, cur_send_size)); TCPSegment cur_seg; cur_seg.payload () = Buffer (std::move (temp_seg_content)); cur_seg.header ().seqno = wrap (_next_seqno, _isn); if (i == seg_num - 1 && _stream.eof ()) cur_seg.header ().fin = true ; _next_seqno += static_cast <uint64_t >(cur_seg.length_in_sequence_space ()); _segments_out.push (cur_seg); _segments_wait.push (cur_seg); cur_bytes_length_in_flight += static_cast <uint64_t >(cur_seg.length_in_sequence_space ()); } return ; } bool TCPSender::ack_received (const WrappingInt32 ackno, const uint16_t window_size) if (ackno - next_seqno () > 0 ) { return false ; } size_t old_rece_free_length = remote_window_size - static_cast <size_t >(cur_bytes_length_in_flight); while (!_segments_wait.empty ()) { if (_segments_wait.front ().header ().seqno - ackno < 0 ) { cur_rto = _initial_retransmission_timeout; continuous_retran_num = 0 ; tcp_timer_running = true ; next_retran_time = cur_all_time + cur_rto; cur_bytes_length_in_flight -= static_cast <uint64_t >(_segments_wait.front ().length_in_sequence_space ()); _segments_wait.pop (); } else { break ; } } if (_segments_wait.empty ()) tcp_timer_running = false ; remote_window_size = static_cast <size_t >(window_size); size_t cur_rece_free_length=remote_window_size-static_cast <size_t >(cur_bytes_length_in_flight); if (cur_rece_free_length>old_rece_free_length && _stream.buffer_size () > 0 ) { fill_window (); } return true ; } void TCPSender::tick (const size_t ms_since_last_tick) cur_all_time += ms_since_last_tick; mytcp_timer (); return ; } void TCPSender::mytcp_timer () if (tcp_timer_running == false ) return ; if (cur_all_time >= next_retran_time && !_segments_wait.empty ()) { _segments_out.push (_segments_wait.front ()); continuous_retran_num++; cur_rto *= 2 ; next_retran_time = cur_all_time + cur_rto; } return ; } unsigned int TCPSender::consecutive_retransmissions () const return continuous_retran_num; }void TCPSender::send_empty_segment () TCPSegment cur_seg; cur_seg.header ().seqno = wrap (_next_seqno, _isn); _segments_out.push (cur_seg); return ; } bool & TCPSender::sender_syn_sent () return syn_sent; }
lab4 tcp connection
把前面的4个lab内容结合起来,实现一个完整的tcp自动机。
需要处理的细节很多很多很多…….
主要就四个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 void connect () size_t write (const std::string &data) void tick (const size_t ms_since_last_tick) void segment_received (const TCPSegment &seg) using namespace std;size_t TCPConnection::remaining_outbound_capacity () const return _sender.stream_in ().remaining_capacity (); } size_t TCPConnection::bytes_in_flight () const return _sender.bytes_in_flight (); } size_t TCPConnection::unassembled_bytes () const return _receiver.unassembled_bytes (); } size_t TCPConnection::time_since_last_segment_received () const return cur_time_since_last_segment_received; } void TCPConnection::segment_received (const TCPSegment &seg) if (!_sender.sender_syn_sent () && !seg.header ().syn && !recv_start) return ; recv_start=true ; if (rst_receved) return ; if (seg.header ().rst){ _receiver.stream_out ().set_error (); _sender.stream_in ().set_error (); _linger_after_streams_finish=false ; rst_receved=true ; active_tcp=false ; } cur_time_since_last_segment_received=0 ; _receiver.segment_received (seg); _sender.ack_received (seg.header ().ackno, seg.header ().win); if (_receiver.stream_out ().input_ended () && !_sender.stream_in ().eof ()) { _linger_after_streams_finish = false ; } if (_sender.segments_out ().empty ()) { if (_receiver.stream_out ().input_ended () && !seg.header ().fin) { } else if (seg.length_in_sequence_space () == 0 ) { } else { _sender.send_empty_segment (); } } send_segments (); } bool TCPConnection::active () const if (_sender.stream_in ().eof () && _sender.bytes_in_flight () == 0 && _receiver.stream_out ().input_ended () && (cur_time_since_last_segment_received >= _cfg.rt_timeout * 10 || _linger_after_streams_finish==false )) return false ; if (rst_receved || !active_tcp) return false ; return true ; } size_t TCPConnection::write (const string &data) size_t writen_num=_sender.stream_in ().write (data); _sender.fill_window (); send_segments (); return writen_num; } void TCPConnection::tick (const size_t ms_since_last_tick) _sender.tick (ms_since_last_tick); cur_time_since_last_segment_received+=ms_since_last_tick; send_segments (); if (_time_wait && cur_time_since_last_segment_received >= _cfg.rt_timeout * 10 ) { _time_wait = false ; recv_start=false ; active_tcp=false ; } if (_sender.consecutive_retransmissions () > _cfg.MAX_RETX_ATTEMPTS) { _sender.stream_in ().set_error (); _receiver.stream_out ().set_error (); _linger_after_streams_finish = false ; while (!_sender.segments_out ().empty ()) { _sender.segments_out ().pop (); } _sender.send_empty_segment (); TCPSegment& seg = _sender.segments_out ().front (); seg.header ().rst = true ; active_tcp=false ; rst_receved=false ; send_segments (); } return ; } void TCPConnection::end_input_stream () _sender.stream_in ().end_input (); _sender.fill_window (); send_segments (); return ; } void TCPConnection::connect () if (!_sender.sender_syn_sent ()){ _sender.fill_window (); TCPSegment& syn_seg = _sender.segments_out ().front (); syn_seg.header ().win = min (_receiver.window_size (), static_cast <size_t >(UINT16_MAX)); _segments_out.push (syn_seg); _sender.segments_out ().pop (); } return ; } void TCPConnection::send_segments () if (!active_tcp || rst_receved) return ; while (!_sender.segments_out ().empty ()) { TCPSegment& seg = _sender.segments_out ().front (); if (_receiver.ackno ().has_value ()) { seg.header ().ack = true ; seg.header ().ackno = _receiver.ackno ().value (); } seg.header ().win = min (_receiver.window_size (),static_cast <size_t >(UINT16_MAX)); _segments_out.push (seg); _sender.segments_out ().pop (); } if (_sender.stream_in ().eof () && _sender.bytes_in_flight () == 0 && _receiver.stream_out ().input_ended ()) { if (_linger_after_streams_finish) { _time_wait = true ; } } return ; } TCPConnection::~TCPConnection () { try { if (active ()) { _sender.stream_in ().set_error (); _receiver.stream_out ().set_error (); rst_receved=true ; active_tcp=false ; _linger_after_streams_finish = false ; while (!_sender.segments_out ().empty ()) { _sender.segments_out ().pop (); } _sender.send_empty_segment (); TCPSegment& seg = _sender.segments_out ().front (); seg.header ().rst = true ; send_segments (); } } catch (const exception &e) { } }
优化 用官方提供的sponge/libsponge/util/buffer.cc中的 BufferList类来作为ByteStream的容器,使得原来基于内存拷贝的存储方法变为基于内存所有权转移。
用c++的 std::move assign 右值引用等新特性对 ByteStream进行改造。